
Elimizdeki veriyi bir çok model üzerinde machine learning için kullanabiliriz. Peki en doğru modelin hangisi olduğunu nasıl anlıcaz. Evaluating regression konusu bu noktada kullanılmaktadır. Burda yapılan tahminin matematiksel olarak değerlendirildiği 0 ve 1 arasında bir sonuç alınır.
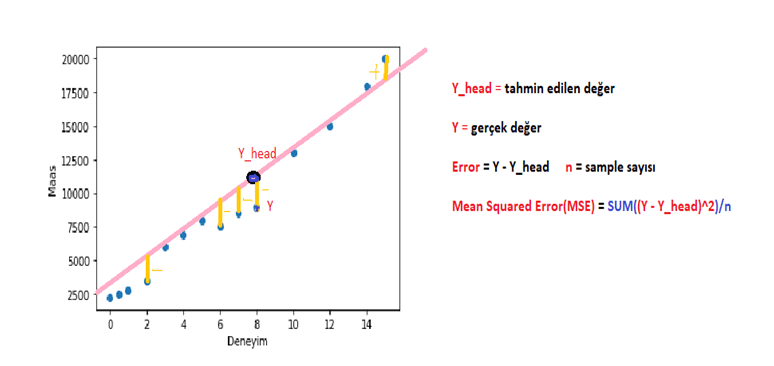
Aslında literaturde error dediğimiz değer residual olarak geçer. Model değerlendirilirken şu işlemler yapılır.
Residual = Y – Y_head
Square Residual = (Y – Y_head)^2
Sum(Square Residual) = Sum((Y – Y_head)^2) –> SSR
Y_avg = a gibi bir değer olsun.
Sum(Square Total) = (Y – Y_avg)^2 –> SST
R_square = 1 – (SSR / SST)
R_square değeri 1’e ne kadar yakınsa model o kadar iyi demektir.
Şimdi, daha önceden kullandığımız Random forest modelini aynı veri seti üzerinde uygulayıp R_square değerini hesaplayalım.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
df = pd.read_csv("C:/MACHINE_LEARNING/RandomForestRegression.csv",
sep = ";",header = None)
x = df.iloc[:,0].values.reshape(-1,1)
y_real = df.iloc[:,1].values.reshape(-1,1)
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators = 100, random_state = 42)
rf.fit(x,y)
y_head = rf.predict(x)
#metrics model değerlendirmelerinde kullanılır.
from sklearn.metrics import r2_score
print("R_score: ", r2_score(y_real,y_head))
#R_score = R_square
output:
R_score: 0.9798724794092587R_square değerinin oldukça iyi olduğunu görüyoruz.
Lineer regression model için R_square değeri hesaplayalım.
import pandas as pd
df = pd.DataFrame(LinearRegressionDatasetcsv,columns=["deneyim","maas"]
#linear regresyon
from sklearn.linear_model import LinearRegression
linear_reg = LinearRegression()
x = df.deneyim.values.reshape(-1,1)
y_real = df.maas.values.reshape(-1,1)
y_predict = linear_reg.predict(x)
#evaluating
from sklearn.metrics import r2_score
print("R_score :",r2_score(y_real,y_predict))
#R_score = R_square
output:
R_score : 0.9775283164949902