
Hive, facebook tarafından büyük verileri sorgulamak, çözümlemek için geliştirilmiş bir veri ambarıdır.
Sql’e çok yakın bir dil olan HQL(Hive Ql ) ile birçok farklı formattaki veriyi sorgulayabiliriz. Hive büyük veriyi sorgulamak için yazılan HQL sorgularını map reduce işlerine(koduna) dönüştürerek , hızlı ve yüksek performanslı çalışmasını sağlamış olur .
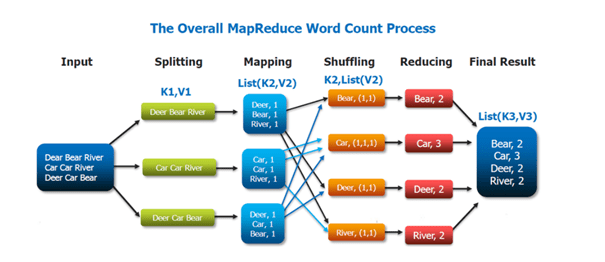
Map reduce mantığı :
HIVE TABLO YAPISI :
Temel olarak iki tablo yapısı bulunur. Manage table and External table
Manage table create etme işlemi :

Tablonun özelliklerine bakalım :

İçine veri atmak için :

External Table create etme işlemi :

Tablonun özelliklerine bakalım :
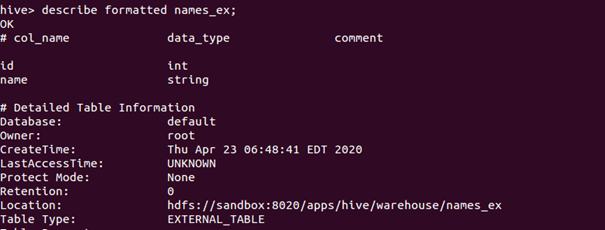
- İki tablonun en önemli farkı eğer manage tabloyu drop edersek o tablonun file yeri de silinir. Ancak bu externel tablo ise sadece tablo silinir file aynen yerinde kalır.
- Hive’da çalışmanın en avantajlı yolu tabloya insert işlemi yapmamıza gerek kalmaz eğer okutacağımız veriyi nifi ile içeri alıp file sisteme yani hdfs’e yazarsak ordan doğrudan hive ile okuma işlemi yaparız file değiştikçe tablonun verisi de değişir.
- Hive ve spark’ın temel farkı spark veri depolama işlemi yapmaz ve memory’i kullandığı için kısıtlıdır. Memory yettiği kadar işlem yapılabilir ancak hive map reduce yaptığı için böyle bir durum söz konusu değildir. Veri büyüdükçe hive performansı daha net farkedilir.
HIVE PARTITIONS
create table state_part
(District string,Enrolments string)
PARTITIONED BY(state string);
Partion işlemi yukarıdaki şekilde yapılır. Önemli olan partition by yapılan kolon adı create table kısmında olmamalı.
SQL’de bir milyonluk tabloya select atıldığı zaman tüm tablo içinden kayıt getirir. Bu tablonun indexli olduğunu da düşünürsek oldukça maliyetli bir durum ile karşılaşıyoruz. Çünkü index verinin %20’si civarında yer tutmaktadır.
Hive’de partition kullanırsak bu durumu engellemiş oluyoruz. Elimizde farklı departmanlarda çalışan kişilerin tutulduğu bir tablo olsun. Eğer departmana partition koyarsak. Hive diyelim ki departmanı A olan kayıtları ayrı bir file içinde departmanı B olanları ayrı bir file içinde tutar. Böylece sorgu çekeceğimiz veri kümesi azalmış olur. Bu da performansı hayli arttırır.
HIVE BUCKETS
Hive bir tabloda id gibi number gibi alanları doğrudan ayrı ayrı gruplar buna bucket denir.Performansı oldukça etkilemektedir.
HIVE SKEWED TABLES
Diyelim ki elimizde Türkiye’nin illeriyle ilgili verileri tuttuğumuz bir tablo olsun. Bu tabloda İstanbul’la ilgili olan veriler oldukça dağınık ve fazla olsun. Diğer iller için bu durum olmasın. Böyle bir tabloda illere göre partition yapmak mantıklı olmaz sadece istanbula göre bölmek istersek skewed table kullanırız.
Örnek bir skewed table :
Create table skew_demo
(
Gender string,
Age int,
Salary double,
Id int
)
Skewed by (id) on (90,100) stored as directories;
Bu sorguda id numaraları 90 ve 100 olan kayıtlar ayrı ayrı dosyalara atılmış oldu.
HIVE FILE FORMAT
Hive’de oluşturduğumuz bir tablonun mutlaka ORC formatında olması gerekmektedir. Diğer veri türlerine göre iki katı performansa sahip olur.
CREATE TABLE names
(id int, name string)
STORED AS ORCFile;
Formatımız ORC olmasa dahi formatını değiştirebiliriz :
ALTER TABLE tablename SET FILEFORMAT ORC;
Hive’de default olarak orc oluşturulur :
SET hive.default.fileformat = Orc
