
RDD (Resilient Distributed Dataset): Spark’ın temelini oluşturur. Herşey RDD üzerinden dönmektedir. Verilen üç sunucuyu spark cluster’ı olarak düşünelim. RDD1 üç parçaya ayrılmış. Bunu bir tablonun veya büyük bir text tablosunun üçte bir parçası olarak düşünelim.
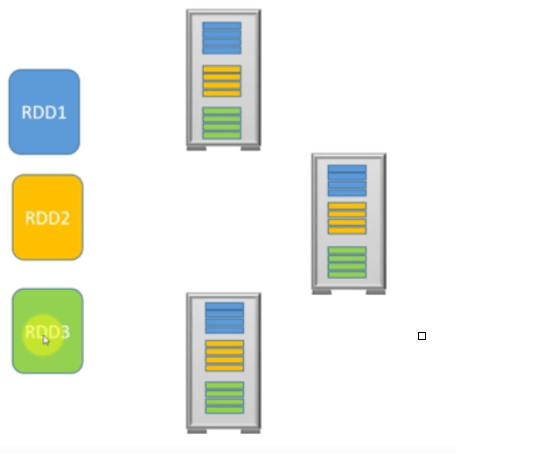
Biz veri üstünde ne yaparsak yapalım asla bu veriler bozulmaz.
Progmımız bozulsa yada hata alsa bile bu veriler kesinlikle kaybolmaz.
Spark çalışma esnasındaki bu diskteki verilerin biz kısmını kendi hafızasına çeker.
– Bir RDD bir çok immutable(sabit,değişmez) nesne yığınlarından oluşur.
– Spark’ta gerçekleşen tüm işler ;
– yeni bir RDD oluşturmak,
– mevcut RDD’yi başka bir RDD’ye dönüştürme
– RDD’ler üzerinde hesaplamalar yapıp bir sonuç üretme
RDD OLUŞTURMAK
1.YOL : Dışarıdan veriyi kullanmak
dosyaRDD = sc.textFile(“C:/dosyam.txt”)
2.YOL : Mevcut bir veriyi parçalayıp cluster üzerine dağıtarak
Sayilar = sc.parallelize((1,2,3,4,5,6,7,8))
1’den 8’e kadar verilmiş bir veriyi dağıtarak sayilar adında bir RDD oluşturmuş oluruz.
RDD OPERASYONLARI

Transformation : RDD üzerinde dönüşümler yapan ve sonucunda başka RDD’ler üreten metodlardır.
Action : RDD’lerden bir sonuç üreten metodlardır.Action olmadan transformation metodları çalışmaz.
Bir uygulama ile RDD mantığını iyice anlamaya çalışalım :
Elimizde 12 insana ait yaş bilgileri olsun. Biz bu yaşların toplamını hesaplamak istiyoruz.

1.komut dosyayı okuyalım :
Val insanlarRDD = sc.textFile(“/user/dosya/insanlar.csv”)Daha sonra üç parçadan oluşan bir datasetimiz oldu.
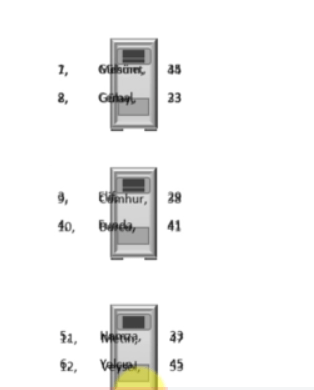
RDD’ yi okuduğumuzda şu şekilde bir liste karşımıza çıkmaktadır.

Bir tarnsformation işlemi daha yapalım. Her bir satırı virgülle olan yerleri ayırıcaz :
Val insanlarSplittedRDD = insanlarRDD.map(x = > x.split(“,”))
Daha sonra dizinin ikinci elemanını toplama işlemi yapıcaz.
insanlarSplittedRDD.map (x => x(2).toDouble ).reduce( (a,b) => a + b)
Daha sonra ayrı ayrı toplamları alır ve sonuş döndürür :

