
Büyük veri için neden farklı platformlara ihtiyacımız var ?
Tek bir bilgisayarla bu kadar çok veriyi işlemeye çalıştığımızı düşünelim :

Bu durumda bilgisayarımız iflas edecektir:

Bu durumun olmaması için yapılması gereken birden fazla makine kullanmak :

Şekilde görüldüğü gibi dört bilgisayar kullanıyoruz. Büyük veri ne yapıyor peki? Bu makinelerin harddiskini, RAM’ini, işlemci gücünü kullanıyor. Bunları bir araya getirip sanki tek bir bilgisayarmış gibi çalışıyor ve büyük veriyi kolaylıkla ve hızlı bir şekilde işlemektedir. Apache spark dünyada bu işi en iyi yapanlardan olup açık kaynaklı veri işleme motorudur.

Spark’ı beş bölüme ayırabiliriz :
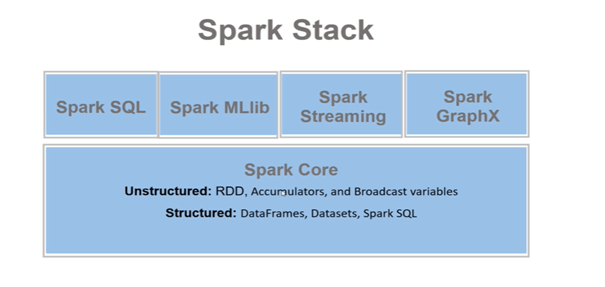
Apache Spark Nedir ?
Bütünleşik bir hesaplama motorudur.
Bilgisayar kümelerinde (cluster) paralel veri işleme için bir dizi kütüphanedir.
Bütünleşik : büyük veri uygulamaları için her türlü ihtiyacı karşılayacak şekilde tasarlandırılmış ve geliştirilmiş olmasıdır.
Veri okuma/yazma, programlama, SQL, makine öğrenmesi, streaming,
Graf analiz, python, scala, java, R gibi hepsiyle aynı motor ve birbirleriyle uyumlu API setlerini içerir.
İnteraktif veri analizi yapabilmektedir. Yani notebook’ta yazdığımız bir kod parçasının sonucunu döndürür.(Apache zeppelin, jupiter)
Spark’ın bir çok veri kaynağı bulunur.Burdan veriyi okuyup hesaplama yapar.Spark veri depolamaz. Mantık şudur : Kodlar verinin ayağına gider.
Veriyi olduğu yerde analiz eder. Gerektiği kadarını Spark kendi cluster belleğine çeker. Yetmediği yerde tekrar veri kaynağına gider, okur ve getirir.
Mekanik diskler :
Ortalama 100 MB/s hız ile
10 sn -> 1 Gb
1dk -> 6 Gb
10 dk -> 60 Gb
1 saat -> 360 Gb
3 saat -> 1 Tb
İki diskten paralel okuma olursa bu süreler yarıya iner.
Ortalama 200 MB/s hız ile
5 sn -> 1 Gb
30 sn -> 6 Gb
5 dk -> 60 Gb
30 dk -> 360 Gb
1.5 saat -> 1 Tb
Ortalama 400 MB/s hız ile
1.25 sn -> 1 Gb
7.5 sn -> 6 Gb
1.25 dk -> 60 Gb
7.5 dk -> 360 Gb
22.5 dk saat -> 1 Tb
Klasik yani dikey mimaride bunun bir sınırı var. Disk ünitesinin bir sınırı var belli bir kapasitesi var ve paralel okumanında bir sınırı var. Bunun çözümü ise yatay ölçekli bir büyüme.

Veriyi yatay şekilde disklere dağıtılır.

Spark, bu sistemi kullandığı gibi ayrica RAM’de kullanır. Burda gerekli gördüğü veriyi oraya çeker. Bu da ona büyük bir hız kazandırmaktadır.
Aynı şekilde bu disklerin farklı sunucularda takılı olduğu düşünülürse bu sunucuların işlemci gücünü de kullanıyor. Bu şekilde büyük veri ile başa çıkıyor.
- Geniş ölçeklidir. Bir bilgisayardan binlerce suncuya kadar veriyi hiçbir değişikliğe uğramadan işleyebilir.
- Dağıtık veri işleme sayesinde yani elindeki terabaytlık verinin her bir parçasını sunuculara böler. Böylece çok hızlı okur, hesap yapmak istediğinde verinin hangi kısmında olacaksa onu taşıyan sunucuya gider orda hesap yapar sonucunu döndürür.Çok kısa sürede hesaplama imkanına sahip olur böylece.
- İki çalışma modu bulunur.
- Cluster Mode : sparkın kendi clusterı ve yöneticisi var. Onun dışında
Hadoop Yarn, kubernetes, Mesos gibi cluster yöneticileri var. Bunlarla da uyumlu çalışır.
- Local Mode : kendi lokalimizde geliştirme yapmaya imkan sağlar.
Cluster nedir ?

Kullanıcıyla etkileşime geçen Edge sunucu, Yönetici sunucular ve işçi sunucular var. Veriler ve hesaplama gücü NodeManager tarafında, diğerleri bu sunucuları yönetir, Edge Node’dan kullanıcı kodunu gönderir. Manager kısmı gerekli cluster kaynaklarını kullanıcıya tahsis eder ve kullancının spark uygulaması node manager kısmında dağıtık bir şekilde çalışır.
