
Spark, büyük ölçekli veri işleme için hızlı ve genel bir motordur. Diğer platformlara kıyasla daha hızlı olmanın sırrı Spark’ın Memory (RAM) üzerinde çalışması ve bu işlemi Disk’ten daha hızlı hale getirmesidir.
Makine öğrenmesi için özel bir kütüphanesi olan MLLib, hem yüksek kalitede algoritmalar( başarıyı artırmak için birden fazla iterasyon yapan) sunar hem de hız( MapReduce’den 100 kat fazla). Kütüphane Java, Scala ve Python’da Spark uygulamalarının bir parçası olarak kullanılabilir.
Şimdi adım adım bakalım :
Emlak sitesinden alınan ev bilgilerinin olduğu bir veri seti kullanıcaz(cal_housing.data). Zeppelin üzerinden işlem yapıyoruz.
1.) Önce veriyi RDD’ye alalım.
# Load in the data
rddR = sc.textFile('/tmp/cal_housing.data')
# Load in the header
headerR = sc.textFile('/tmp/cal_housing.domain')
2.) Veri setindeki header içinde ne var bakalım.
# Veri setinin tüm öğelerini sürücü programında bir dizi olarak döndürür.
%livy2.pyspark
headerR.collect()
output:
[u'longitude: continuous.', u'latitude: continuous.', u'housingMedianAge: continuous. ', u'totalRooms: continuous. ', u'totalBedrooms: continuous. ', u'population: continuous. ', u'households: continuous. ', u'medianIncome: continuous. ', u'medianHouseValue: continuous. ']3.) Veri setimizin ilk iki satırına bakalım :
rddR.take(2)
#u- ile başlayıp diğer u’ya kadar devam eden kısım ilk satır.
output:
[u'-122.230000,37.880000,41.000000,880.000000,129.000000,322.000000,126.000000,8.325200,452600.000000', u'-122.220000,37.860000,21.000000,7099.000000,1106.000000,2401.000000,1138.000000,8.301400,358500.000000']Map işlemini yapalım :
%livy2.pyspark
# Split lines on commas
rddR = rddR.map(lambda line: line.split(","))
# Inspect the first 2 lines
rddR.take(2)output:
[[u'-122.230000', u'37.880000', u'41.000000', u'880.000000', u'129.000000', u'322.000000', u'126.000000', u'8.325200', u'452600.000000'], [u'-122.220000', u'37.860000', u'21.000000', u'7099.000000', u'1106.000000', u'2401.000000', u'1138.000000', u'8.301400', u'358500.000000']]4.) RDD’ye aldığımız verinin tüm satırlarını alıp dataframe haline getiricez.
#toDF işlemi RDD’yi dataframe haline getirir yani üzerinde işlemleri yapabileceğimiz daha düzgün bir hale getirir.
from pyspark.sql import Row
dfR = rddR.map(lambda line: Row(longitude=line[0],
latitude=line[1],
housingMedianAge=line[2],
totalRooms=line[3],
totalBedRooms=line[4],
population=line[5],
households=line[6],
medianIncome=line[7],
medianHouseValue=line[8])).toDF()
5.) Dataframe’in 20 satırına bakarsak
%livy2.pyspark
# Show the top 20 rows
dfR.show()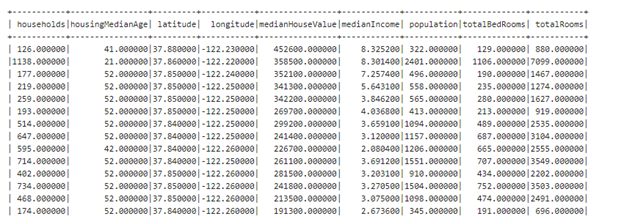
6.) Dataframe’in semasına bakalım.
%livy2.pyspark
# Print the data types of all `df` columns
# df.dtypes
# Print the schema of `df`
dfR.printSchema()
7.) Bu veri seti ile machine learning yapılabilmesi için string ve null veri tipi olmaması gerek. Bu nedenle verileri dönüştürücez.
%livy2.pyspark
from pyspark.sql.types import *
dfR = dfR.withColumn("longitude", dfR["longitude"].cast(FloatType())) .withColumn("latitude", dfR["latitude"].cast(FloatType())) .withColumn("housingMedianAge",dfR["housingMedianAge"].cast(FloatType())) .withColumn("totalRooms", dfR["totalRooms"].cast(FloatType())) .withColumn("totalBedRooms", dfR["totalBedRooms"].cast(FloatType())) .withColumn("population", dfR["population"].cast(FloatType())) .withColumn("households", dfR["households"].cast(FloatType())) .withColumn("medianIncome", dfR["medianIncome"].cast(FloatType())) .withColumn("medianHouseValue", dfR["medianHouseValue"].cast(FloatType()))
8.) Yukarıdaki dönüşümü farklı bir metodla yapabiliriz :
%livy2.pyspark
# Import all from `sql.types`
from pyspark.sql.types import *
# Write a custom function to convert the data type of DataFrame columns
def convertColumn(df, names, newType):
for name in names:
df = df.withColumn(name, df[name].cast(newType))
return df
# Assign all column names to `columns`
columns = ['households', 'housingMedianAge', 'latitude', 'longitude', 'medianHouseValue', 'medianIncome', 'population', 'totalBedRooms', 'totalRooms']
# Conver the `df` columns to `FloatType()`
dfR = convertColumn(dfR, columns, FloatType())9.) Herhangi iki kolonuna bakmak istersek :
%livy2.pyspark
dfR.select('population','totalBedRooms').show(10)output :
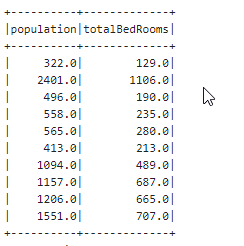
10.) Gruplama yapmak istersek :
%livy2.pyspark
dfR.groupBy("housingMedianAge").count().sort("housingMedianAge",ascending=False).show()output:
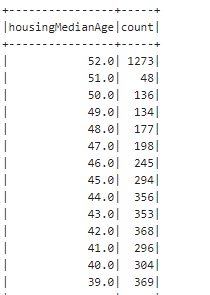
11.) Kolonların içeriğine detaylıca bakalım :
%livy2.pyspark
dfR.describe().show()output :

12.) Verilere baktığımızda medianHouseValue değeri çok büyük . Modele verdiğimizde sağlıklı sonuç alamayabiliriz bu nedenle küçültme işlemi yapıcaz. Amaç verinin daha anlamlı hale gelmesi.
%livy2.pyspark
# Import all from `sql.functions`
from pyspark.sql.functions import *
# Adjust the values of `medianHouseValue`
dfR = dfR.withColumn("medianHouseValue", col("medianHouseValue")/100000)
# Show the first 2 lines of `df`
dfR.take(2)output:
[Row(households=126.0, housingMedianAge=41.0, latitude=37.880001068115234, longitude=-122.2300033569336, medianHouseValue=4.526, medianIncome=8.325200080871582, population=322.0, totalBedRooms=129.0, totalRooms=880.0), Row(households=1138.0, housingMedianAge=21.0, latitude=37.86000061035156, longitude=-122.22000122070312, medianHouseValue=3.585, medianIncome=8.301400184631348, population=2401.0, totalBedRooms=1106.0, totalRooms=7099.0)]13.) Elimizdeki verileri işimize yarayacak yeni veriler üretmek için kullanalım :
%livy2.pyspark
# Import all from `sql.functions` if you haven't yet
from pyspark.sql.functions import *
# Divide `totalRooms` by `households`
#
roomsPerHousehold = dfR.select(col("totalRooms")/col("households"))
# Divide `population` by `households`
populationPerHousehold = dfR.select(col("population")/col("households"))
# Divide `totalBedRooms` by `totalRooms`
bedroomsPerRoom = dfR.select(col("totalBedRooms")/col("totalRooms"))
# Add the new columns to `df`
dfR = dfR.withColumn("roomsPerHousehold", col("totalRooms")/col("households")) \
.withColumn("populationPerHousehold", col("population")/col("households")) \
.withColumn("bedroomsPerRoom", col("totalBedRooms")/col("totalRooms"))
# Inspect the result
dfR.first()output:
Row(households=126.0, housingMedianAge=41.0, latitude=37.880001068115234, longitude=-122.2300033569336, medianHouseValue=4.526, medianIncome=8.325200080871582, population=322.0, totalBedRooms=129.0, totalRooms=880.0, roomsPerHousehold=6.984126984126984, populationPerHousehold=2.5555555555555554, bedroomsPerRoom=0.14659090909090908)14.) Makine öğrenmesine göndereceğimiz kolonları seçelim :
%livy2.pyspark
# Re-order and select columns
dfR = dfR.select("medianHouseValue",
"totalBedRooms",
"population",
"households",
"medianIncome",
"roomsPerHousehold",
"populationPerHousehold",
"bedroomsPerRoom")15.) DenseVector kütüphanesini import edicez.
%livy2.pyspark
# Import `DenseVector`
from pyspark.ml.linalg import DenseVector
# Define the `input_data`
#X[0] DEDİĞİ LABEL olarak tanımladığımız kolon X[1:] DEDİĞİ 1 DEN BAŞLAYIP SONUNA KADAR GİT ONLARDA FEATURES olarak tanımladığımız kolonlar
input_dataR = dfR.rdd.map(lambda x: (x[0], DenseVector(x[1:])))
# Replace `df` with the new DataFrame
dfR = spark.createDataFrame(input_dataR, ["label", "features"])16.) StandardScaler kütüphanesini import edicez :StandardScaler() özellikleri (X’in her sütunu) normalleştirir, böylece her sütun/özellik/değişken mean = 0 ve standard deviation = 1 olur.
%spark2.pyspark
# Import `StandardScaler`
from pyspark.ml.feature import StandardScaler
# Initialize the `standardScaler`
standardScaler = StandardScaler(inputCol="features", outputCol="features_scaled")
# Fit the DataFrame to the scaler
scaler = standardScaler.fit(df)
#transformasyonda sonuç verir.
#tarnsform = predict
# Transform the data in `df` with the scaler
scaled_df = scaler.transform(df)
#scled df'yi test ve train olarak böldük
# Inspect the result
scaled_df.take(2)output :
[Row(label=4.526, features=DenseVector([129.0, 322.0, 126.0, 8.3252, 6.9841, 2.5556, 0.1466]), features_scaled=DenseVector([0.3062, 0.2843, 0.3296, 4.3821, 2.8228, 0.2461, 2.5264])), Row(label=3.585, features=DenseVector([1106.0, 2401.0, 1138.0, 8.3014, 6.2381, 2.1098, 0.1558]), features_scaled=DenseVector([2.6255, 2.1202, 2.9765, 4.3696, 2.5213, 0.2031, 2.6851]))]17.) Veriyi test ve train olarak ikiye bölücez :
%spark2.pyspark
# Split the data into train and test sets
train_data, test_data = scaled_df.randomSplit([.8,.2],seed=1234)18.) Lineer regresyon yöntemiyle machine learning yaparsak :
%spark2.pyspark
import warnings
from pyspark.ml.regression import LinearRegression
lr = LinearRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# Fit the model
# modeli makineye öğretiyoruz.
lrModel = lr.fit(test_data)
#tahmin işlemini yapıyor
predicted = lr.predict(test_data)19.) Son olarak modelimizin başarısını göreceğimiz parametreleri hesaplamak için :
# Print the coefficients and intercept for linear regression
print("Coefficients: %s" % str(lrModel.coefficients))
print("Intercept: %s" % str(lrModel.intercept))
# Summarize the model over the training set and print out some metrics
trainingSummary = lrModel.summary
print("numIterations: %d" % trainingSummary.totalIterations)
print("objectiveHistory: %s" % str(trainingSummary.objectiveHistory))
trainingSummary.residuals.show()
print("RMSE: %f" % trainingSummary.rootMeanSquaredError)
print("r2: %f" % trainingSummary.r2)
# Coefficients for the model
linearModel.coefficients
# Intercept for the model
linearModel.intercept
# Get the RMSE
linearModel.summary.rootMeanSquaredError
# Get the R2
linearModel.summary.r2